Author: Ing. Slavomír Skopalík
Date: 7.5.2015
This document covers techniques for reducing Database (DB) size and improving the performance of Firebird (FB) SQL 3.0 by replacing an outdated record fragment compression with a better one.
When I changed the character set from WIN1250 to UTF-8, DB size increased from ~75GB to ~90GB. Database performance was slightly reduced as well.
During analysis I found that the current schema can handle one block of up to 128 bytes. This is effective if you have an unpacked record size less than ~1kB. For larger records lengths you create huge overhead. For example, 32000 bytes of zeros (null VARCHAR) is packed as 500 bytes. If this block is incompressible, size will increase by 250 bytes.
The UTF-8 character set is a great common standard to minimize the size of data. In the worst case, one character occupies 4 bytes of memory. FB calculates using the worst situation and allocates 4 bytes for each character in the record buffer.
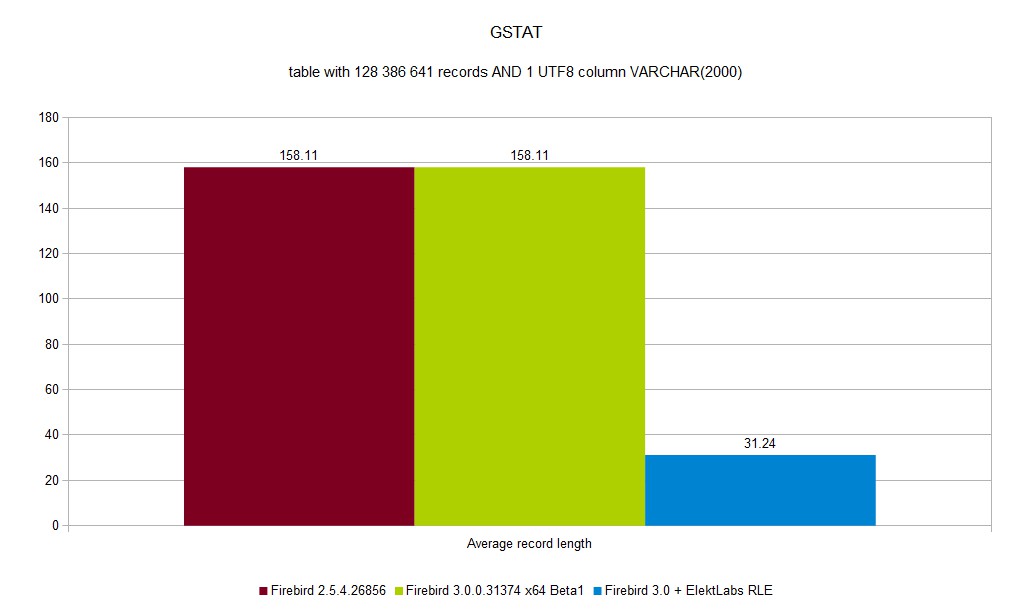
For example, VARCHAR(2000) in character set WIN1250 will occupy 2002 bytes, but for UTF-8 will occupy 80002 bytes.
8000 bytes in current IT is a really small block, but if you have 100M of these blocks, the situation becomes very different.
To handle a record buffer like this one, I prepared a much more effective compression schema that focuses on effective compression of zeros.
Elekt Labs RLE is designed to handle three different blocks (zeros, repeated byte and uncompressed block) in three different lengths (1 byte header, 2 bytes header and 3 bytes header) that can handle a record buffer up to 1MB.
Writing performance gain comes from less IO, compression encoding has similar complexity.
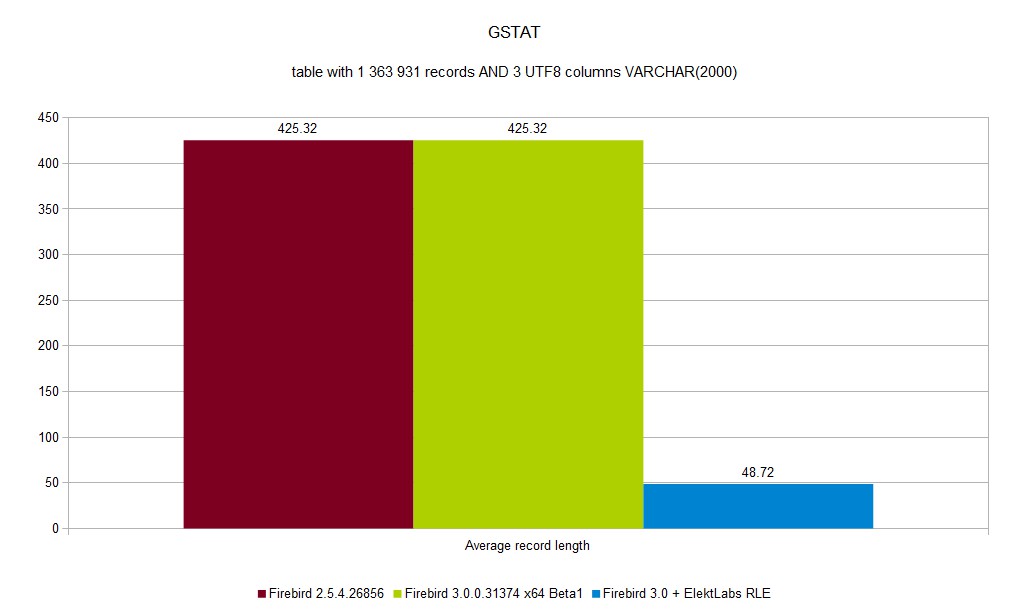
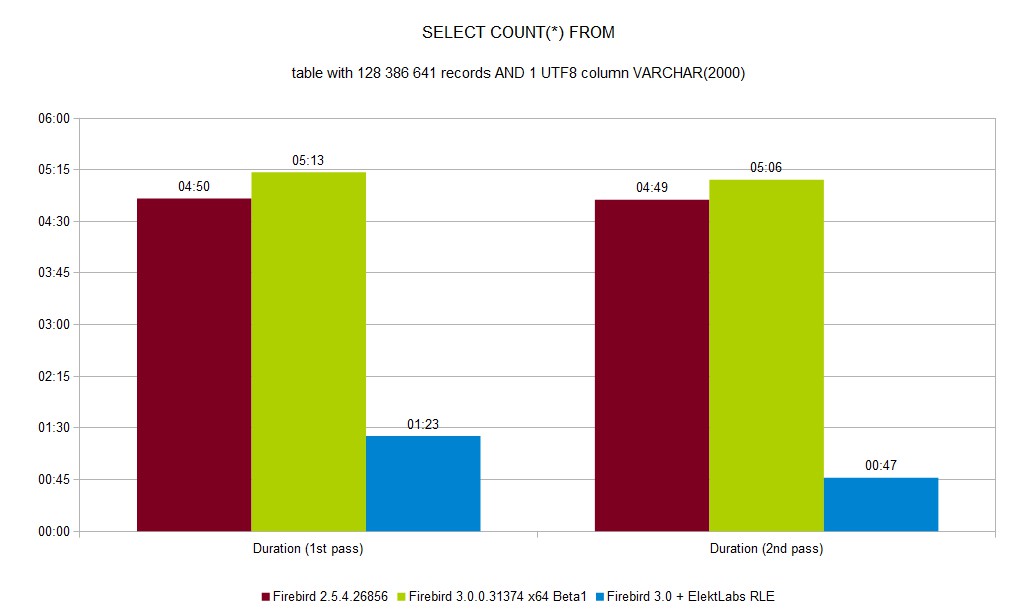
Reading gain is a result of two separate gains. The first one, because there is much more dense data on data page, about 30% of our databases is saved. This creates much more hits into all caches (Firebird internal, OS, disk controller) as you can see in SELECT COUNT(*) second pass duration. The second gain comes from using a well implemented memory move and memory set functions in c/c++. This function works much better on larger sizes than on smaller sizes (SSE instructions is used).
We created tests that are focused on comparing WIN1250 and UTF-8.
We created a database and in this database one table:
CREATE TABLE a(
a VARCHAR(8000))
Once for character set NONE, once for character set WIN1250 and once for UTF-8.
We ran this test under version 2.5.4, official 3.0 beta1 and our private build from SVN revision 61366.
Insertion of 100M of NULL values decreased from 1:51:29 to 32:21 (~3.5X faster). This speed up is because of the increased data density (more records on a data page, nothing else).
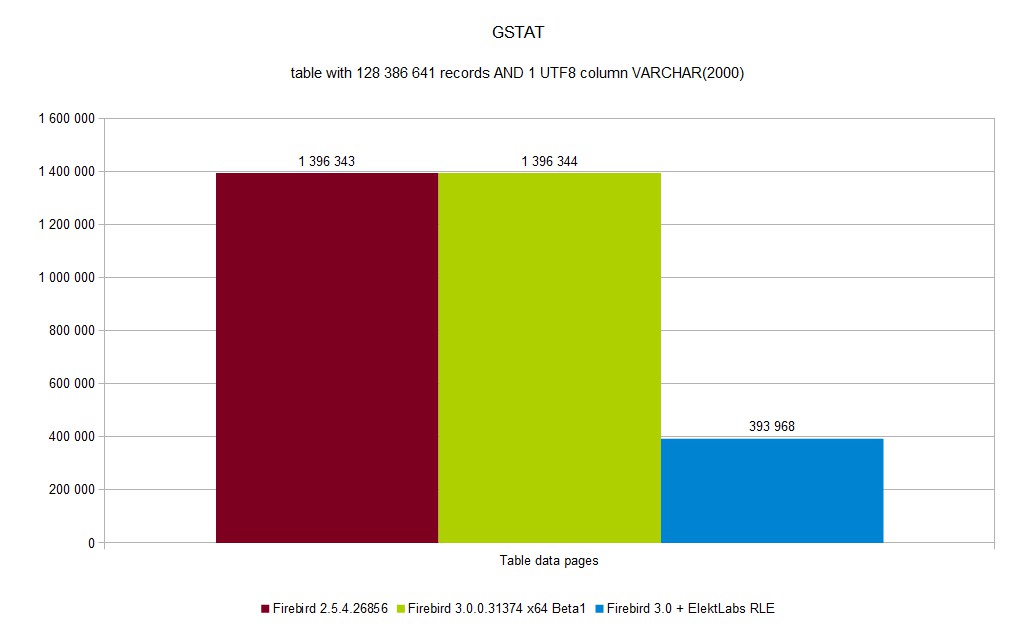
Database size was reduced from ~52GB to 5GB
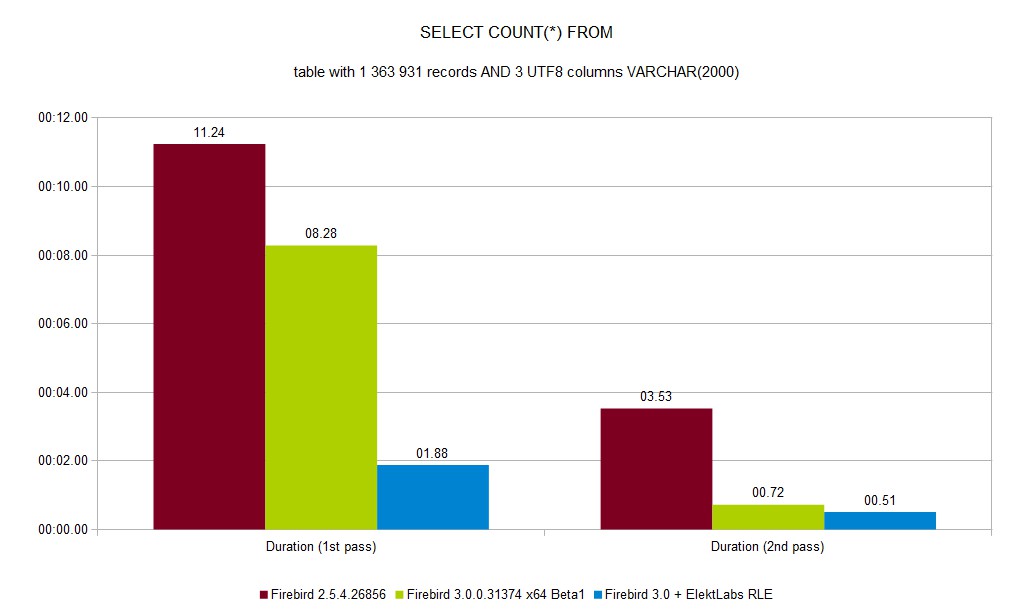
SELECT COUNT(*) from inserted table decreased from 11:48 to 0:48 (~14.7 faster).
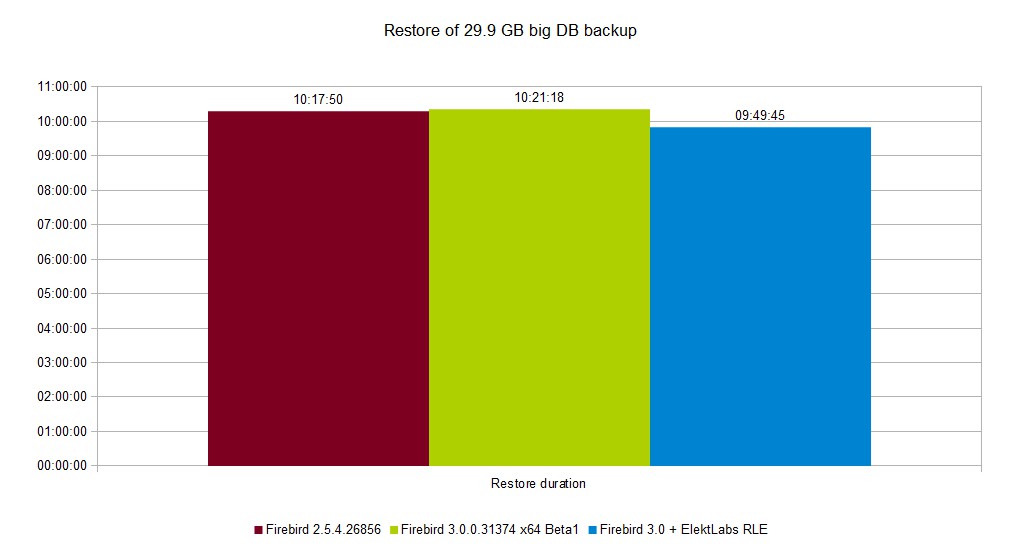
Restore of real database backup decreased from 10:21:18 to 9:49:45, saving 32 minutes.
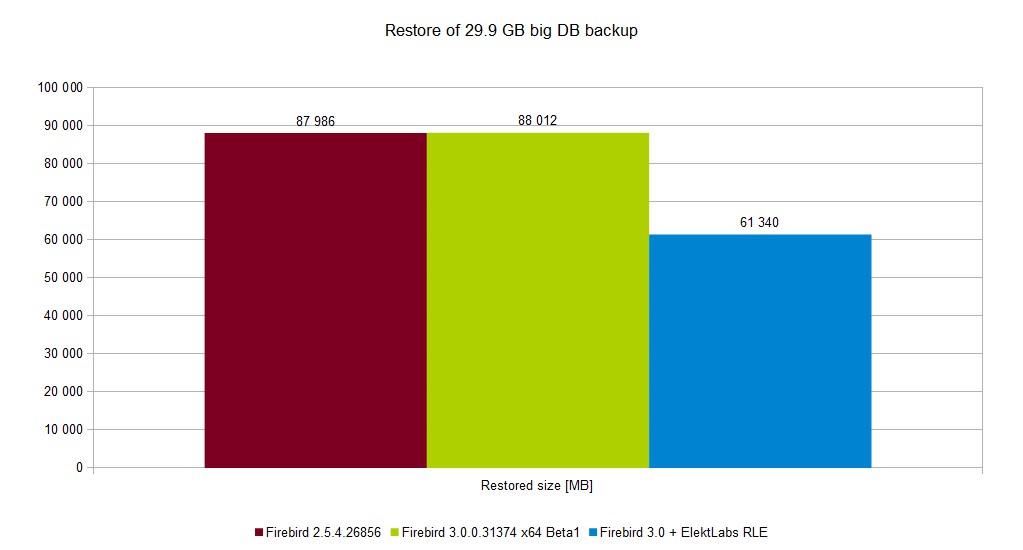
DB size was reduced from ~88GB to ~61GB
SELECT COUNT(*) decreased from 8.28s to 1.88 (~4.4 faster)
You can see a full set of graphs in the gallery. As you can see, Elekt Labs RLE is always faster and produces smaller DB size.
My failure: I'm a programmer and I may be a good one, but I'm new to Open Sources cooperation. I promise that this new RLE (if I prepare it quickly) will be included in Firebird 3.
When I finished my work, including test script, this appeared (15.3.2015):
"First of all, your code does not compile on my box. There should be no UINT32 / MAXINT32 there, Firebird native typedefs SLONG/MAX_SLONG should be used.
Second, please favor our coding style:
http://www.firebirdsql.org/en/coding-style/
Code without separating spaces like "if(size==1)" or "cc2=(nc>>5)&0x7F" is unreadable and thus unacceptable.
Also, I feel a "break" is missing here:
case RLE_cmp:
RLE_WriteCmp(n, space_n, 0, np);
RLE_WriteCmp(nr, space_nr, 0, np);
default:
BUGCHECK(178); // msg 178 record length inconsistent
break;
Finally, after fixing everything, compilation hangs on GCC at the lang_helpers rule. AFAIU, this new encoding is not backward compatible, so older databases (already created during the build) cannot be processed. If so, this may be OK for v4 but not for v3.
I believe for v3 we'll have to try your simpler RLE modification, the one which is backward compatible."
- Dmitry
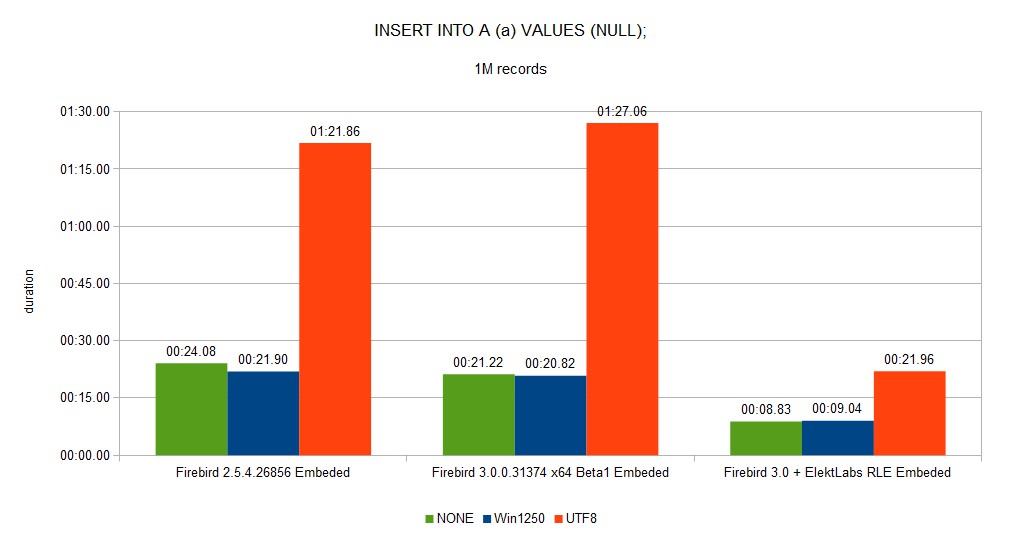
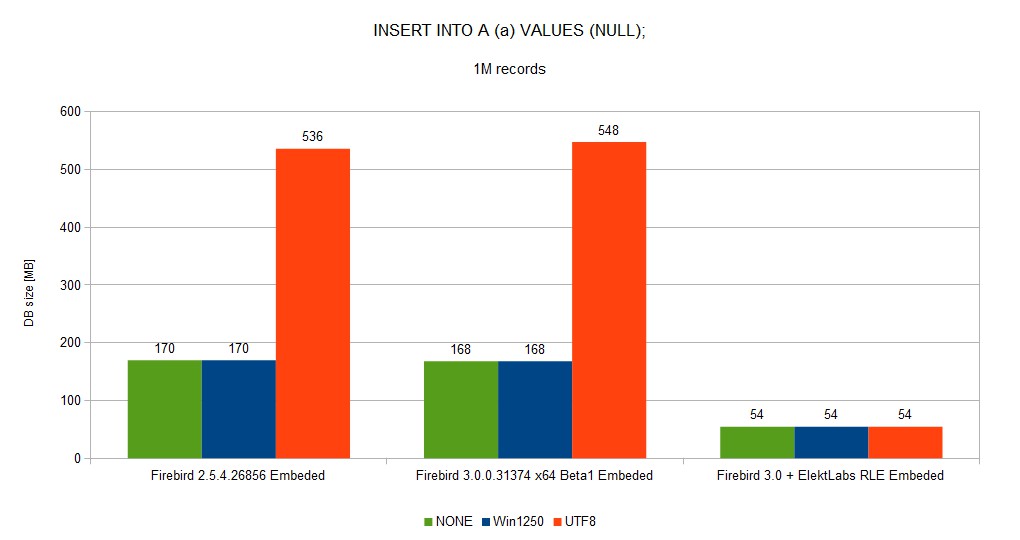
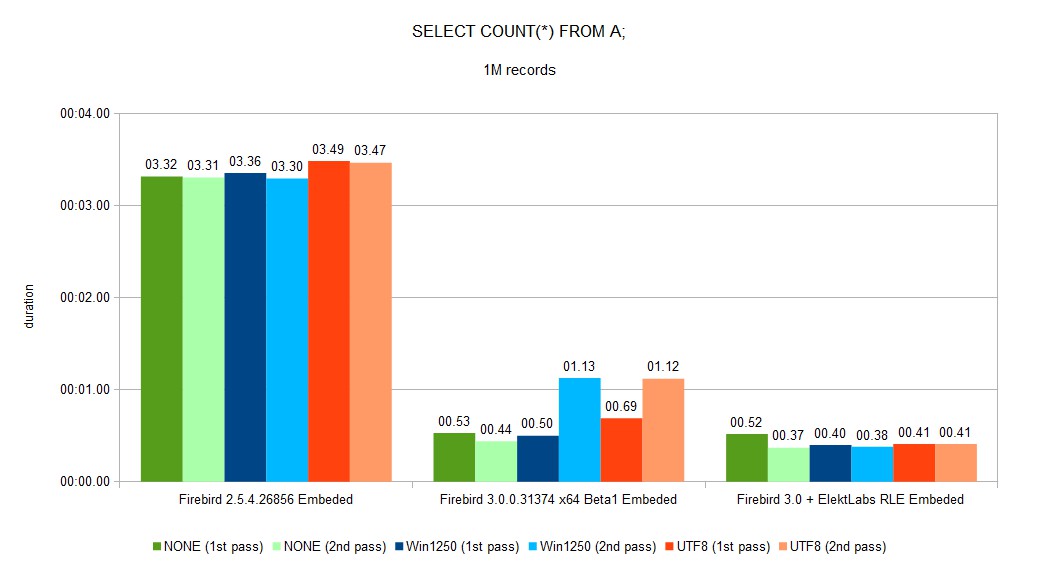
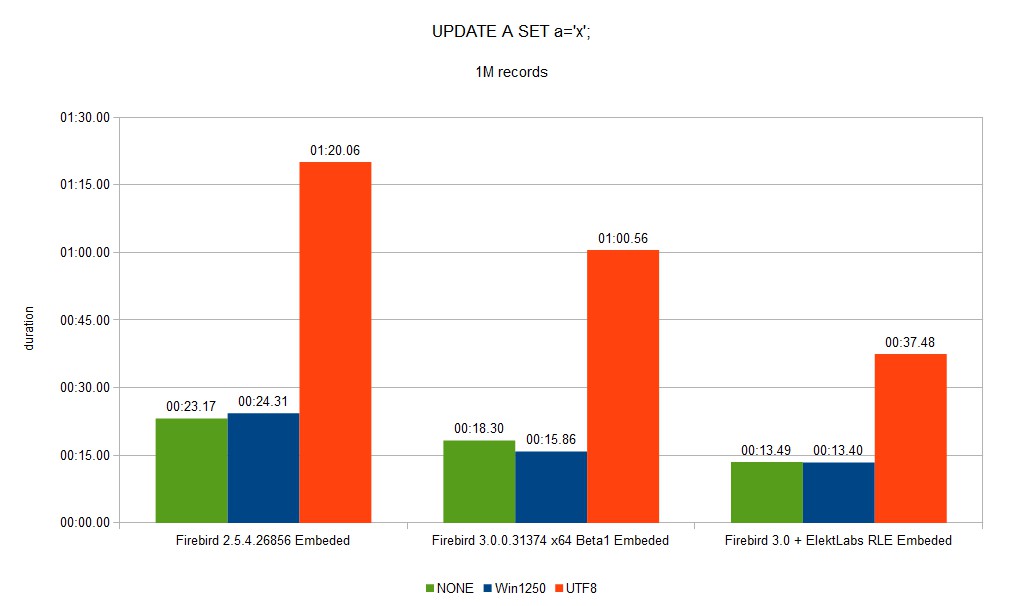
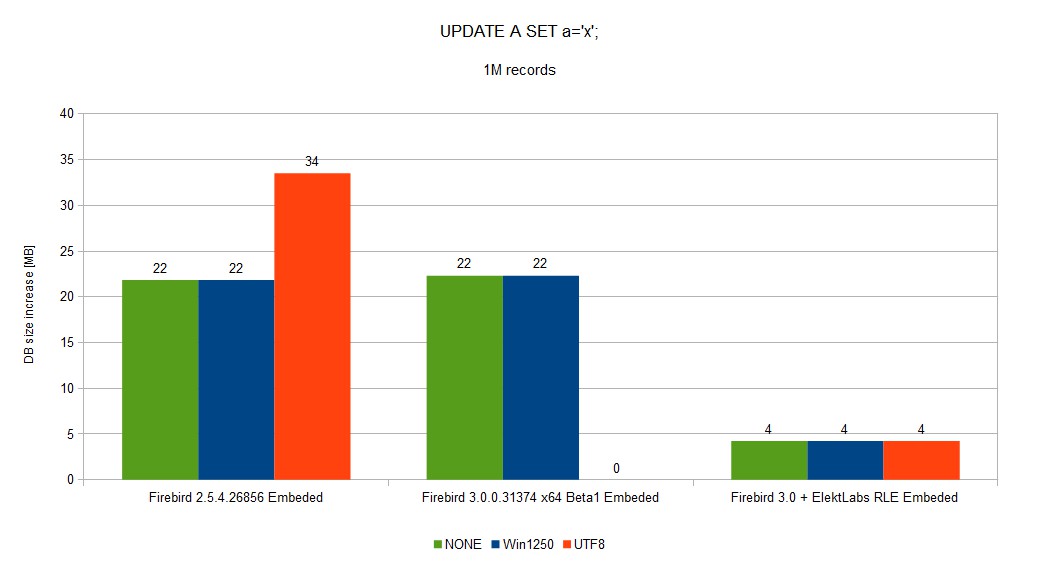
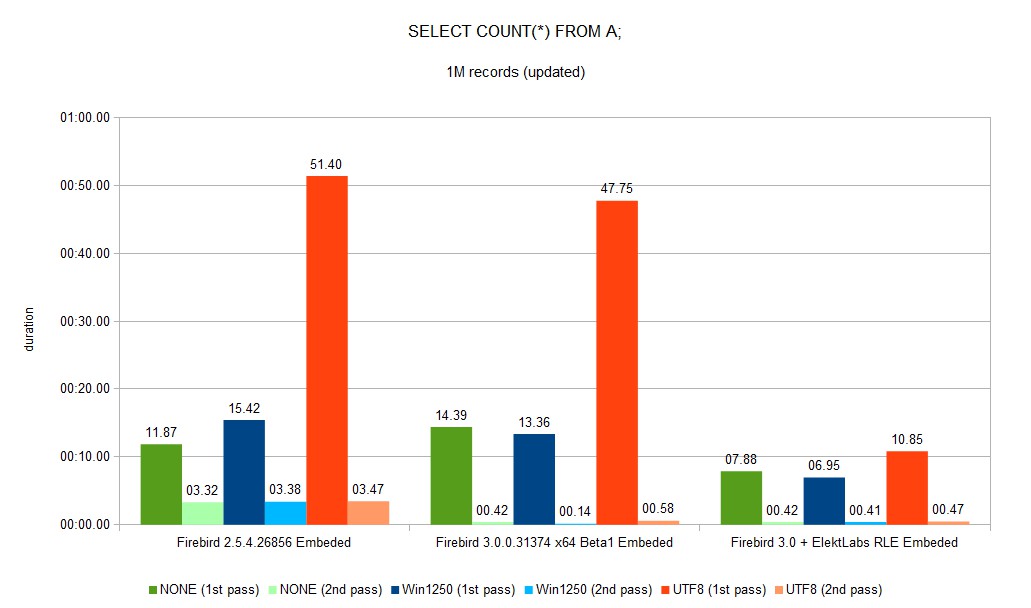
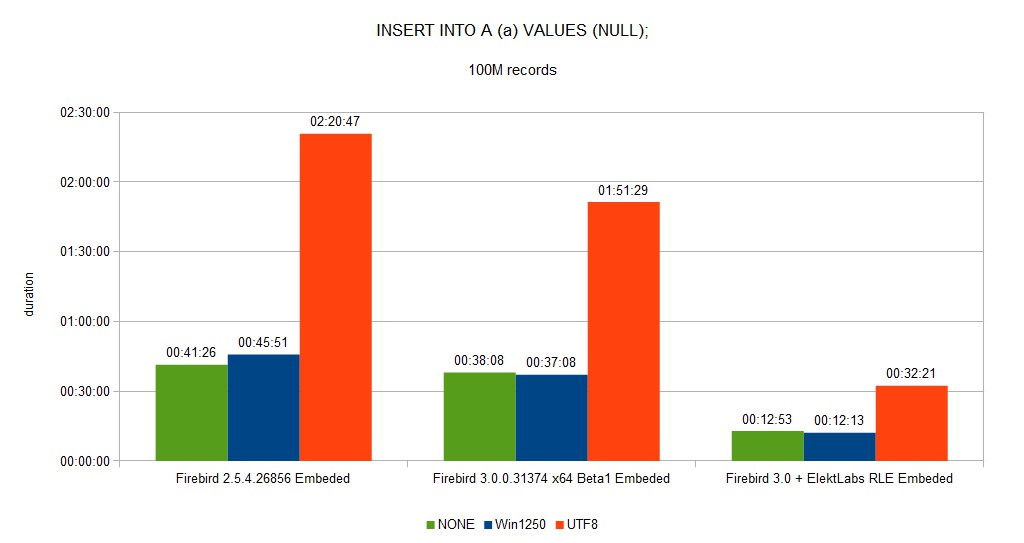
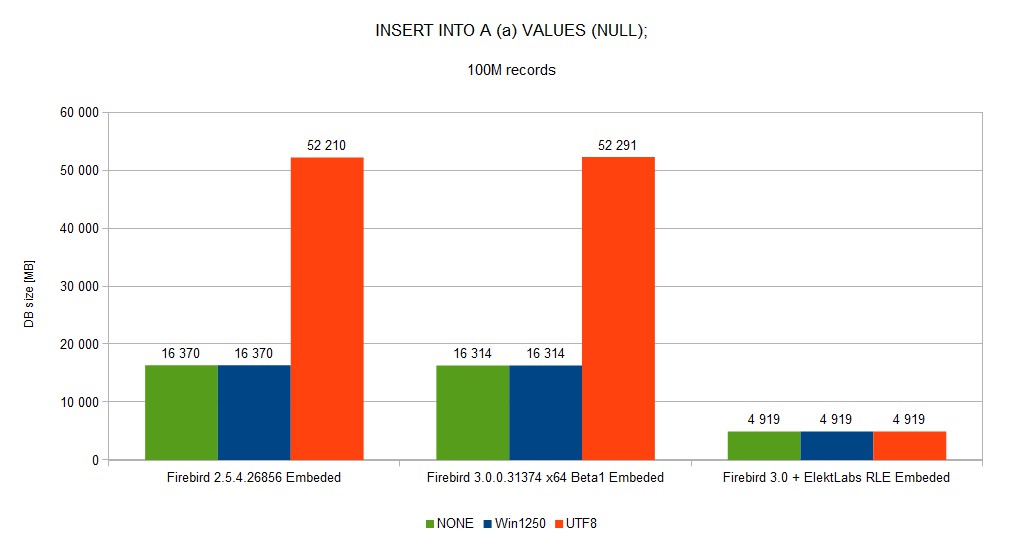
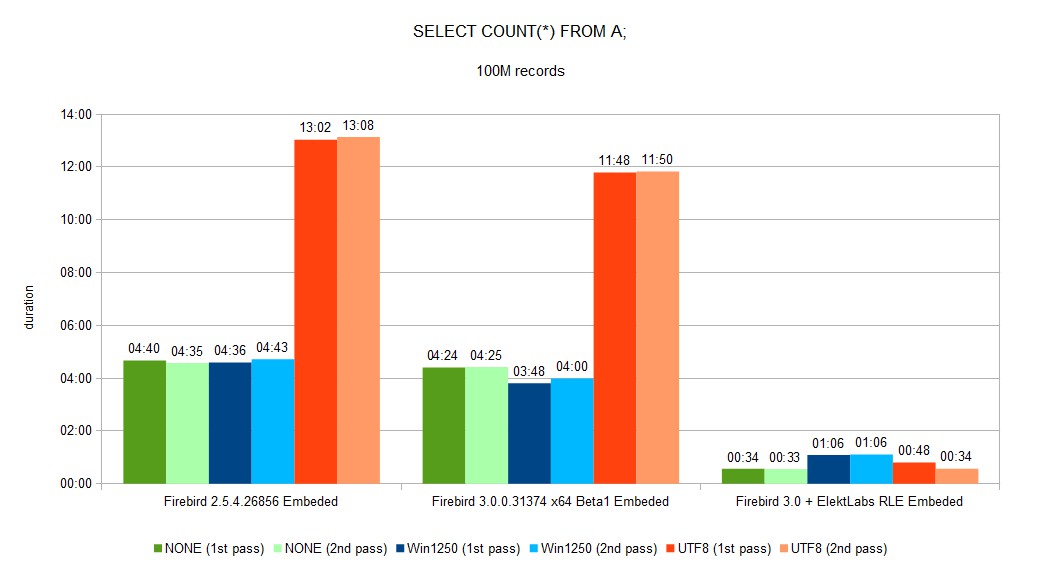
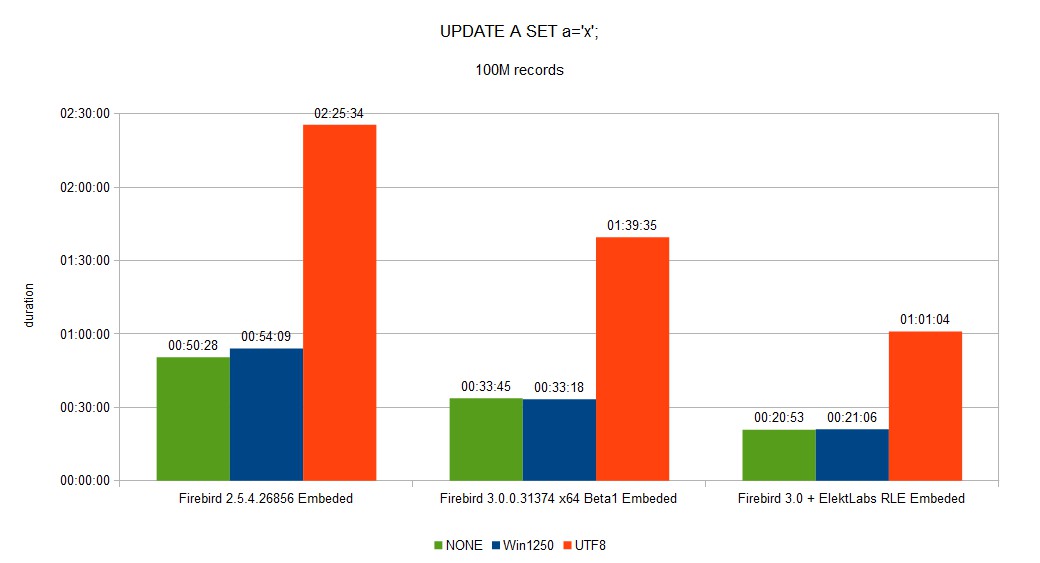
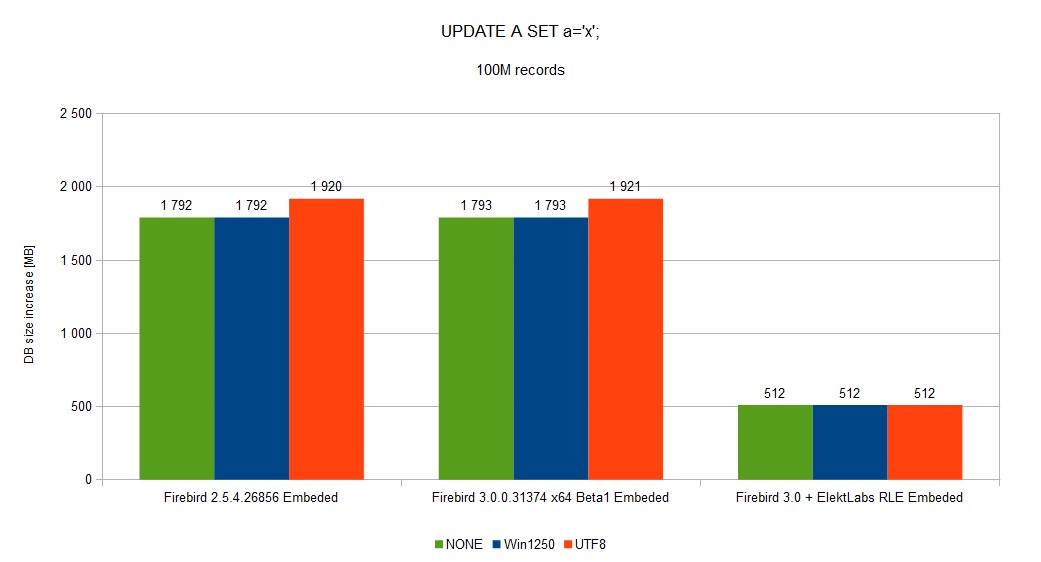
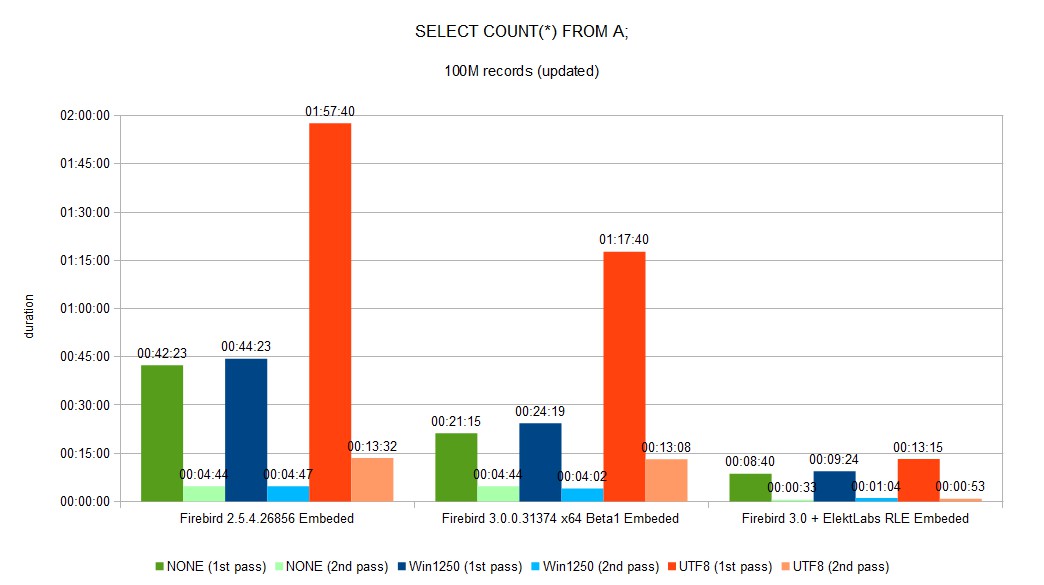

We created a fork of the Firebird project when we built our version for us and our customer. 30% reduction of DB size and speed gain between few % to 10x is very important.
We will publish our fork for free. Enjoy it!
If someone is interested, we can back port this feature to FB 2.5.x series (it is faster and stable).
Feel free to contact us.
Upon further analysis of the internal FB, we learned that we can prepare better compression/encoding than I present here. However, this change will be more invasive to the Firebird source code.
FirebirdWin64_ElektLabs.zip - Sources and all necessary binaries for Windows x64(SVN revision 61366)